Does LLM Size Influence Believability?

One important use of AI-generated content is to persuade. Whether this is done through political arguments generated by Large Language Models (LLMs) or through slop from AI image generators, the goal is largely the same: to get people to believe things that may or may not be accurate.
Last week, a group of researchers at Stanford published some new findings in PNAS concerning the ability of LLMs to generate cogent and believable arguments based on the size of the LLM.
The authors note that:
LLMs can generate compelling propaganda and disinformation, durably alter belief in conspiracy theories, draft public communications as effective as those from actual government agencies, and write political arguments as persuasively as lay humans and perhaps even political communication experts. Further, while LLMs offer new potential for personalized, microtargeted messaging and prolonged multiturn dialogue, research has demonstrated that even exposure to brief, static, nontargeted messages can have equivalent (and significant) persuasive impact on people’s attitudes.
The question these researchers sought to answer was whether larger LLMs produced "better" results when it comes to making a persuasive argument.
LLM size is measured in parameters. In machine learning, a parameter defines relationships between objects (data) that are submitted to the model and the outcomes the model produces. In short, parameters determine how input data is used to make predictions or some desired outcome.
As any good statistician knows, models that have lots and lots of parameters can often be overfit. Overfitting is a term that first emerged among statisticians in the 1930s. It refers to a modeled outcome that hews so closely to its training data (i.e., the data used to generate the parameters themselves) that it fails to predict external or future observations reliably.
Another word for overfitting is over-parameterization. An overfitted model has too many parameters than can be justified by its outcomes. When we encounter overfitted models, Occam's Razor typically suggests that we opt for one with fewer parameters – one that will still reliably predict observations in the training data, but will predict external observations perhaps even more reliably.
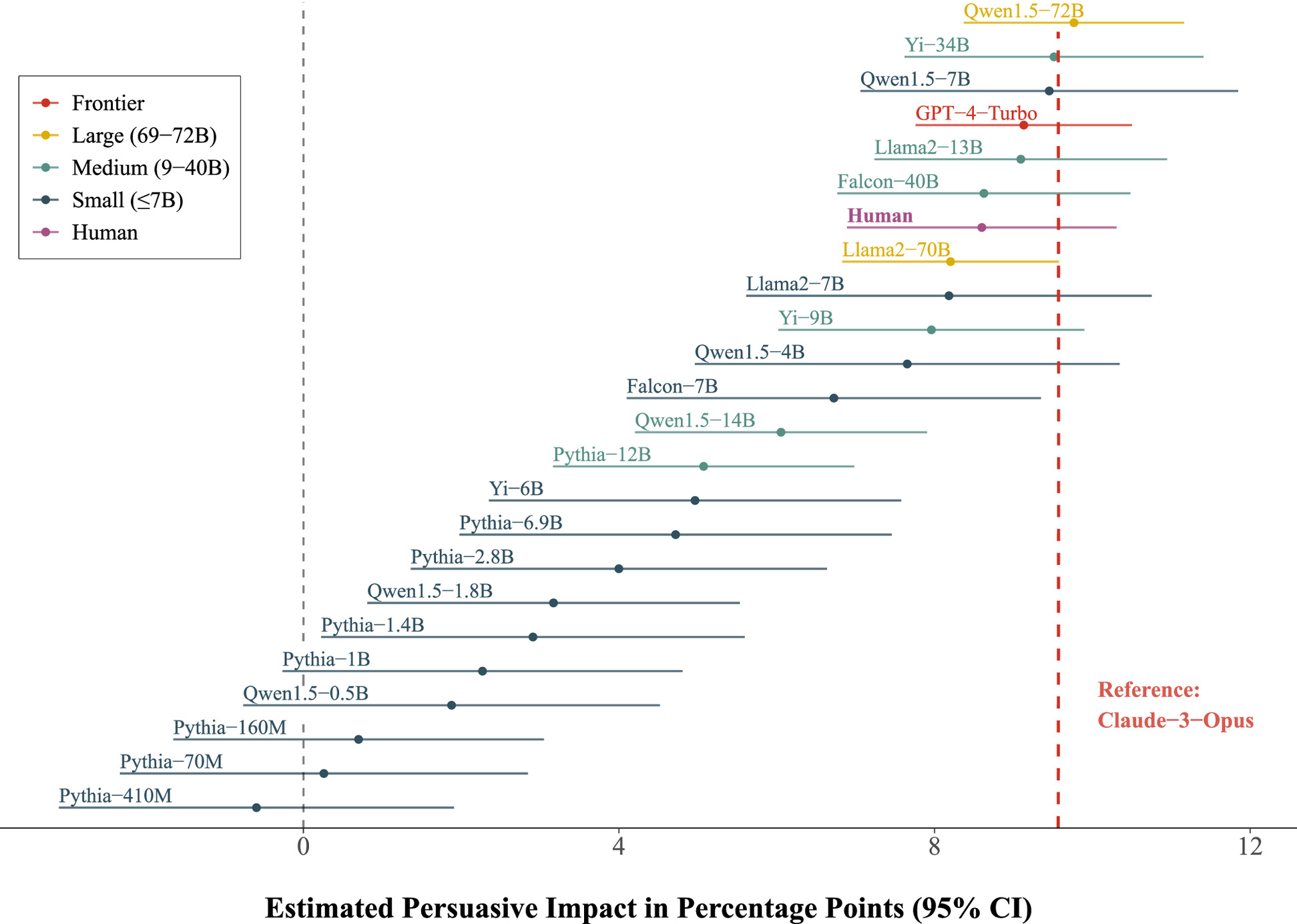
Currently, LLMs range in size from fewer than 100 million parameters (Pythia) up to about 300 billion parameters (Claude-3-Opus, GPT-4-Turbo), or maybe even more since the cutting-edge models are not open-source. Models that contain fewer than about 7 billion parameters are considered "small" by industry standards, but even those models require a fair amount of computing resources to run.
Does this difference in size of several orders of magnitude really affect outcomes, such as the believability of content produced by the models?
To a certain extent, the authors of the Stanford study found that size does matter. Larger models have more persuasive impact. But, they also found that there were some major diminishing returns in the very largest models. Claude-3-Opus and GPT-4-Turbo did not produce outcomes that were significantly more persuasive than a human benchmark or even several LLMs that had a small fraction the number of parameters. Qwen1.5, with 7 billion parameters, and Llama2, with 13 billion parameters, performed just as well as the much larger cutting-edge models.
Why, apart from overfitting, might that be the case?
The researchers explored several potential factors separate from the number of parameters that might explain the persuasive impact of the models. Some of these included message length, readability, proportion of moral language used, and proportion of emotional language used.
The authors hypothesized that,
perhaps larger models are more persuasive because they use more emotional or moral rhetoric or because they write longer, more detailed messages than smaller models—thereby providing more new information or causing greater message elaboration among the audience.
They also explored how well each model simply completed the task asked of it. In other words, how legible the message was in terms of proper use of punctuation, grammar, etc., and whether the generated message was on-topic, or did it write about the issue and advocate for the specific position that was requested of it.
They ultimately found that the effect of task completion completely mitigated the effect of model size. The smallest models produced less persuasive messages because they were less likely to complete the tasks asked of them (i.e., they were too small to string together coherent messages that spoke to the issue or argument). Once the models were conditioned on their ability to generate coherent, on-topic messages, size no longer mattered in the ability of a model to produce persuasive messages.
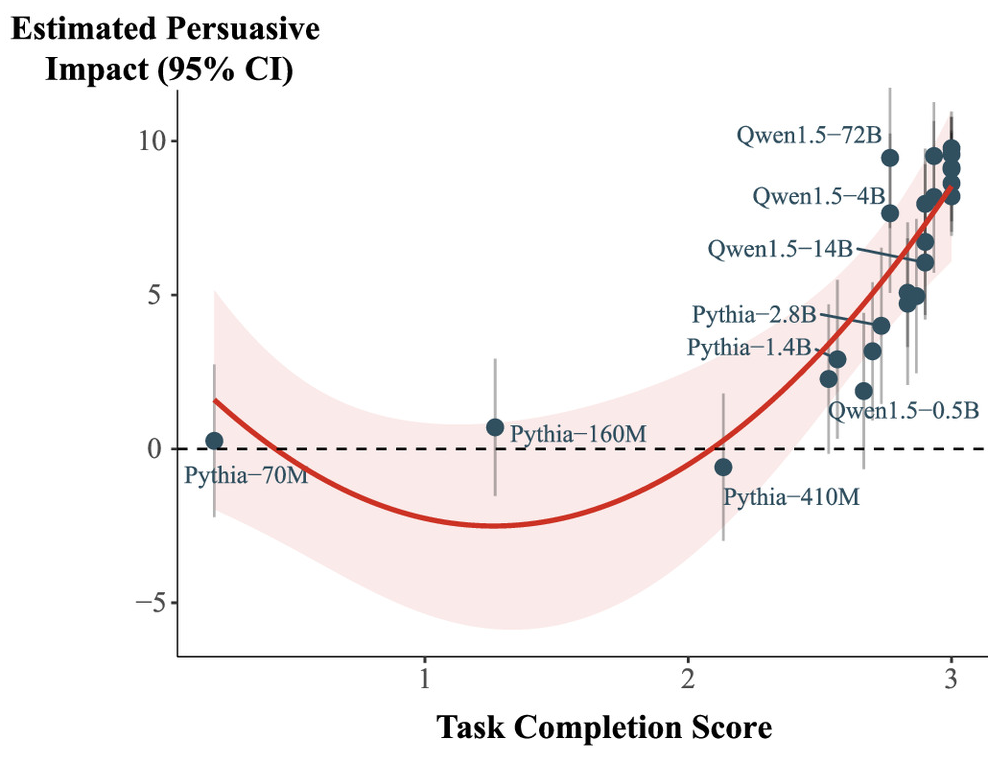
I'm not sure that we should read the results of this study as something that fills us with hope for the future. On the one hand the study suggests that massive LLMs may not be required for AI propagandists to get their messages across. This suggests that the huge amount of computing resources needed to run the largest LLMs may not be necessary if the aim is to persuade an audience.
On the other hand, it also suggests that messages need not be accurate or even truthful in order to be believable. They just need to be well-written (or well-spoken).

I think we've known about this feature of propaganda for a long time. Many examples from pop-culture play on it. The Simpsons episode "Marge vs. the Monorail" from 1993 itself is derived from Meredith Wilson's Broadway hit "The Music Man" from 1957. Even Donald Trump made his claim to fame as a "well-spoken executive" in Mark Burnett's "The Apprentice." Hucksters and flim-flam men and women abound in history. Elizabeth Holmes didn't even need a real product to raise over $700 million from investors.
I'm somewhat troubled, but not surprised, to learn that it seems that we can increase the believability of AI-generated messaging not by increasing the size of the models but by, more simply, ensuring that the statements are coherent and speak to the issue we ask about.
Member discussion